6. GAN - Generative Adversarial Network¶

6.1. Einführung¶
„GAN is the most interesting and coolest idea in the last ten years in machine learning“ - Yann LeCun
2014 von Ian Goodfellow erfunden und in seinem Paper Generative Adversarial Networks ausgearbeitet.
GAN ist ein Algorithmus für unüberwachtes Lernen zweier neuronaler Netze, der teilweise überwachtes Lernen einsetzt.
GANs lernen eine Art ”verstecke Repräsentation“ von Klassen.
GANs ermöglichen die Generierung täuschend echter Fakedaten aller möglichen Strukturen. (Audio, Bild, Text, Zeitreihen, …)
Training oft schwer und ohne Konvergenz
Aktuell exponentieller Anstieg von wisschenschaftlichen Veröffentlichungen und revolutionärer Anwendungen in fast allen Bereichen.
In Anlehnung an Turing-Test wird die GAN-Methodik auch als „Turing-Lernen“ bezeichnet.
Nicht zu verwechseln mit Adversarial Attacks. (Austricksen eines NN durch für Menschen unsichtbare Datenmanipulation)
Ein Generative Adverserial Network (GAN) ist ein künstliches neuronales Netzwerk (ANN) aus dem Bereich der generativen Modelle. Die Aufgabe des GANs ist es, die Wahrscheinlichkeitsverteilung von Trainingsdaten zu erlernen und dadurch anschließend neue, täuschend echte Samples aus dieser Wahrscheinlichkeitsverteilung zu generieren. Außerdem erhofft man sich, den extrem hohen Datenaufwand beim Training neuronaler Netze umgehen zu können, indem durch GANs beliebig viele, hochwertige Trainingsdaten generiert werden können.
6.2. Generative Modelle¶
Die Kernidee hinter generativen Modellen besteht darin, die zugrundeliegende Verteilung der gewünschten Daten zu erfassen und darauf basierend ähnlichen Output zu erzeugen. Diese Verteilung kann nicht direkt beobachtet werden, sondern muss aus den Trainingsdaten näherungsweise abgeleitet werden. Im Laufe der Jahre sind viele solcher Techniken entstanden, die darauf abzielen, Daten zu generieren, die den Eingabestichproben ähnlich sind. Allgemein gehalten können jegliche Typen von Daten wie Text, Bild oder Audiodateien fur generative Modelle herangezogen werden. Es gibt unterschiedliche Typen von generativen Modellen, welche sich vom Aufbau des neuronalen Netzwerks, dem Training und der Zielfunktion unterscheiden.
Beispiele generativer Modelle:
- AE - AutoEncoder:Reduzieren Eingaben auf einfache Repräsentation, um daraus auf unüberwachte Weise ähnliche Daten zu rekonstruieren.
- VAE - Variational AutoencodersFügen AutoEncoder generativere Techniken hinzu.
- RBM - Restricted Boltzmann MachineBidirektionales stochastisch lernendes neuronales Netz bestehend aus zwei Schichten.Nach Forward-Pass wird durch Backward-Pass der Output generiert.
- DBM - Deep Belief NetworksKomposition aus mehreren Autoencodern oder RBMs zum unüberwachten Rekonstruieren der Input-Daten.
- GAN - Generative Adversarial NetworksVerwenden (ursprünglich) weißes Rauschen als Eingabe, um neue Daten zu generieren.
- CycleGANZyklisches Wechselspiel zweier GANs, um unüberwachtes Lernen zu ermöglichen und Training zu stabilisieren.
In den letzten Jahren entwickelte sich das GAN-Konzept (und seine Weiterentwicklungen) durch seine performante Trainierbarkeit und hohe Qualität der generierten Daten zum aktuell besten praktikablen Ansatz aller generativen Modelle.
6.3. Funktionsweise von GANs¶
Zwei kompetitive neuronale Netze - generativ vs. diskriminierend - betreiben ein Nullsummenspiel, wobei der Gewinn des einen den Verlust des anderen Netzes bedeutet. Eines generiert Kandidaten (Generator), das andere (Diskriminator) versucht diese von den echten Trainingsdaten zu unterscheiden. Die Ziel des Generators besteht darin, Ergebnisse zu erzeugen, die der Diskriminator nicht von realen Daten unterscheiden kann. Je besser der Generator im Laufe des Trainings wird, desto genauer wird auch der Diskriminator. Das wechselseitige Lernen durch den Output des jeweiligen Gegenspielers führt iterativ zu besseren Ergebnissen, bis der Generator schließlich täuschend echte Fake-Daten produziert. Dies ermöglicht es dem Modell, auf unüberwachte Weise zu lernen.

6.3.1. Diskriminator¶
Der Diskriminator (D) betreibt simple Klassifikation.
D versucht, reale Daten von den durch G erzeugten Daten zu unterscheiden.
Echte Daten tragen positives Label (1), generierte Daten tragen negatives Label (0). (50/50 pro Batch ist ideal)
Während des Trainings von D trainiert G nicht. Seine Gewichte bleiben konstant, während er Beispiele für das Training von D erzeugt.
D kann jedes beliebiges Modell verwenden, das für die Art der Daten, das es klassifiziert, geeignet ist. (CNN, RNN, SVM, LSTM, …)
D ignoriert während dem Training den Generator-Loss und verwendet nur den Diskriminator-Loss.

Training des Diskriminators:
D klassifiziert sowohl echte Daten (1) als auch gefälschte Generator-Daten (0).
Diskriminator-Loss bestraft D für Fehlklassifizierung im Training.
D aktualisiert (nur) seine eigenen Gewichte durch Backpropagation ausgehend vom Diskriminator-Loss.
6.3.2. Generator¶
Generator (G) bekommt Rauschen als Eingabe.
Dimension der Eingabe meist deutlich kleiner als Dimension des Ausgaberaums
G lernt, daraus plausible Daten zu erzeugen, indem er das Feedback von D einbezieht.
Ziel von G ist das Überlisten von D.
Training komplexer, da G nicht direkt mit seinem Loss verbunden ist.
Generierte Samples werden zu negativen Trainingsbeispielen für D.

Training des Generators:
Generatorausgabe aus Zufallsrauschen erzeugen.
Diskriminator-Klassifizierung real(1) oder fake(0) für die Generatorausgabe ermitteln.
Generatorverlust aus Diskriminator-Klassifizierung berechnen.
D aktualisiert (nur) seine eigenen Gewichte durch Backpropagation ausgehend vom Diskriminator-Loss.
Backpropagation durch Diskriminator und Generator, um Gradienten zu erhalten.
Gradienten verwenden, um NUR die Generatorgewichte anzupassen.
6.3.3. GAN Training¶
Generator und Diskriminator werden abwechselnd trainiert, da sie unterschiedliche Trainingsprozesse haben.
Während Training vom Generator wird Diskriminator konstant gehalten und vice versa!
Dieses konkurrierende Hin und Her bildet den große Vorteil des GAN-Konzepts.
GAN-Konvergenz ist schwer zu erkennen und eher ein flüchtiger Zustand.
6.3.4. Loss Funktion¶
Verlustfunktion gibt den Abstand zwischen der Verteilung der generierten Daten und der Verteilung der realen Daten wieder.
GAN hat zwei Verlustfunktionen, eine für G und eine für D
minimax loss:
G versucht, die folgende Funktion zu minimieren, während D versucht, sie zu maximieren.
Die Formel leitet sich aus der Kreuzentropie zwischen realer und generierter Verteilung ab.
x = Trainingsdaten
z = Eingangsrauschen
D(x) = Schätzung des Diskriminators für Trainingsdaten.
G(z) = Ausgabe des Generators für gegebenes Rauschen z.
D(G(z)) = Schätzung des Diskriminators für Wahrscheinlichkeit, dass gefälschte Instanz echt ist.
Generator versucht D(G(z)) zu maximieren, während Diskriminator gegenläufig versucht (1 - D(G(z))) zu maximieren.
6.4. DCGAN Implementierung¶
15.000 Trainingsdaten aus Flickr Faces Dataset
Auflösung 96 x 96 x 3 (RGB)
Eingangsrauschen hat 100 Elemente
Lossfunktion: Binary Cross Entropy
Epochen: 50
Batchgröße: 32,
Opimizer: Adam mit Lernrate 0.00015

6.4.1. Generator¶
def build_generator(seed_size, channels):
g = Sequential()
# Input Seed >> Fully Connected Layer
g.add(Dense(4*4*256, activation="relu", input_dim=seed_size))
g.add(Reshape((4,4,256)))
# 3 Deconvolution Layers
for filter in [256, 256, 128]:
g.add(UpSampling2D())
g.add(Conv2D(filter, kernel_size=3, padding="same"))
g.add(BatchNormalization(momentum=0.8))
g.add(Activation("relu"))
# Create Output Size
g.add(UpSampling2D(size=(GENERATE_RES,GENERATE_RES)))
g.add(Conv2D(128, kernel_size=3, padding="same"))
g.add(BatchNormalization(momentum=0.8))
g.add(Activation("relu"))
# Final CNN Layer
g.add(Conv2D(channels, kernel_size=3, padding="same"))
# tanh produces output between [-1,1] analog to training_data
g.add(Activation("tanh"))
return g

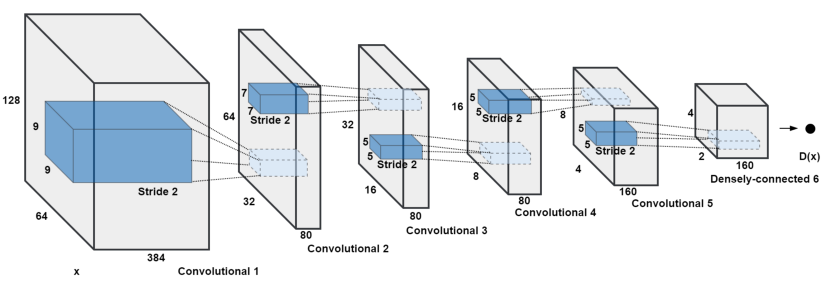
6.4.2. Discriminator¶
def build_discriminator(image_shape):
d = Sequential()
d.add(Conv2D(32, kernel_size=3, strides=2, input_shape=image_shape, padding="same"))
d.add(LeakyReLU(alpha=0.2))
# Convolution Layer
d.add(Dropout(0.25))
d.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
d.add(ZeroPadding2D(padding=((0,1),(0,1))))
d.add(BatchNormalization(momentum=0.8))
d.add(LeakyReLU(alpha=0.2))
# Convolution Layer
d.add(Dropout(0.25))
d.add(Conv2D(128, kernel_size=3, strides=2, padding="same"))
d.add(BatchNormalization(momentum=0.8))
d.add(LeakyReLU(alpha=0.2))
# 2 Convolution Layer
for filter in [256, 512]:
d.add(Dropout(0.25))
d.add(Conv2D(filter, kernel_size=3, strides=1, padding="same"))
d.add(BatchNormalization(momentum=0.8))
d.add(LeakyReLU(alpha=0.2))
d.add(Dropout(0.25))
d.add(Flatten())
# Probability - Real or Fake [0-1]
d.add(Dense(1, activation='sigmoid'))
return d
6.4.3. Loss Funktionen¶
# Helper function to compute cross entropy loss
cross_entropy = tf.keras.losses.BinaryCrossentropy()
# Training_Data >> always 1
# Generated_Data >> always 0
def discriminator_loss(real_out, fake_out):
real_loss = cross_entropy(tf.ones_like(real_out), real_out)
fake_loss = cross_entropy(tf.zeros_like(fake_out), fake_out)
total_loss = real_loss + fake_loss
return total_loss
# Generated_Data >> always 1
# Tries to maximise fake_loss from discriminator
def generator_loss(fake_out):
return cross_entropy(tf.ones_like(fake_out), fake_out)
6.4.4. Training¶
@tf.function
def train_step(images):
# Random Normal Distribution for every Image
seed = tf.random.normal([BATCH_SIZE, SEED_SIZE])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
# Generator Feed Forward
gen_images = generator(seed, training=True)
# Diskriminator Feed Forward: 50/50 Real - Fake
real_output = discriminator(images, training=True)
fake_output = discriminator(gen_images, training=True)
# Loss
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
# Gradienten
gen_gradients = gen_tape.gradient(gen_loss, generator.trainable_variables)
disc_gradients = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
# Adjust Weights for G and D separately !!!
g_optimizer.apply_gradients(zip(gen_gradients, generator.trainable_variables))
d_optimizer.apply_gradients(zip(disc_gradients, discriminator.trainable_variables))
return gen_loss,disc_loss
def train(dataset, epochs):
for epoch in range(0,epochs):
epoch_start = time.time()
g_loss_list = []
d_loss_list = []
# Batch Training
for image_batch in dataset:
t = train_step(image_batch)
g_loss_list.append(t[0])
d_loss_list.append(t[1])
6.4.5. Ergebnis¶
In jeder Epoche wurde der Generator mit 42 stets selben Seed-Werten getestet, um so den Fortschritt vergleichbar zu dokumentieren:

6.5. Probleme beim GAN-Training¶
Wie die anderen generativen Modelle haben auch GANs noch Schwächen bezüglich ihrer Trainingsabläufe und der Qualität der generierten Daten.
6.5.1. Equilibrium¶
Ich tue das Beste, was ich kann, unter Berücksichtigung dessen, was du tust.Du tust, unter Berücksichtigung dessen, was ich tue, das Beste, was du tun kannst.
Diskriminator und Generator betreiben ein gegenseitiges MinMax Spiel. Beide versuchen das Nash-Equilibrium zu erreichen, bei dem sich keiner der beiden Spieler durch einseitiges Abweichen seiner Strategie individuell besser stellen kann. Es wurde gezeigt, dass das Erreichen dieses Gleichgewichts sehr schwierig ist, da durch die Gewichtupdates mit den Gradienten der Loss-Funktion starke Schwingungen enstehen können. Dies kann zur Instabilität im laufenden Training und dazu führen, dass das Modell nie konvergieren wird.
6.5.2. Vanishing Gradient¶
Wenn der Diskriminator zu perfekt trainiert ist - also alle echten sowie generierten Daten korrekt klassifiziert, würde die Loss-Funktion auf 0 fallen und es gäbe keine Gradienten, mit denen die Gewichte des Generators angepasst werden könnten. Dies verlangsamt den Trainingsprozess bis hin zu einem kompletten Stop des Trainings. Würde der Diskriminator allerdings zu schlecht trainiert, bekommt der Generator kein sinnvolles Feedback über seine Leistung bei der Datengeneration und hat keine Möglichkeit die Wahrscheinlichkeitsverteilung der Trainingsdaten zu erlernen.
6.5.3. Mode Collapse¶
Normalerweise sollte ein GAN eine große Vielfalt an Ausgaben erzeugen. Während des Trainings kann es allerdings dazu kommen, dass der Generator auf eine Einstellung seiner Gewichte fixiert wird und es zu einem sogenannten Mode Collapse kommt. Dies hat zur Folge, dass der Generator nur wenige, sehr ähnliche Samples produziert, die viele Duplikate beinhalten. Die gewünschte Varianz an Ergebnissen wird nicht erreicht und das Modell stagniert in ständiger Überanpassung.
6.5.4. Fehlende Evaluations-Metriken¶
Die Loss Funktion der GANs liefert keine aussagekräftige Evaluationsmöglichkeit über den Fortschritt des Trainings. Bei klassifizierenden Modellen im herkömmlichen Machine Learning besteht die Möglichkeit, Test- bzw. Validierungsdaten zu verwenden und anhand dieser die Genauigkeit des Modells zu bestimmen. Bei GANs fällt diese Möglichkeit durch die andersartige Funktionsweise leider weg. Es besteht keine Möglichkeit, den Trainingsfortschritt und die relative oder absolute Qualität des Modells allein anhand des Verlusts objektiv zu beurteilen. Die Evaluation muss entweder anhand manueller Beurteilung oder anderer Verfahren bewerkstelligt werden. (Inception Score, FID)
6.6. Einsatzgebiete und Anwendungsbeispiele¶
photorealistische Bilder / Videos / Kunst / Mode / Deepfakes
Musik & Sprachsynthese
3D-Modelle aus Bildern erzeugen
Bildrekonstruktion
Style-Transfer
Modellierung von Bewegungsmustern
wissenschaftliche Vorhersagen & Berechnungsoptimierung von Simulationen in Teilchenphysik & Astronomie
extrem schnell wachsende Anzahl und Diversität an Anwendungen

6.6.2. GauGAN - Gauguin GAN by NVIDIA¶

6.6.3. CAN - Creative Adversarial Network¶
Im Oktober 2018 wurde erstmals ein maschinell erstelltes Kunstwerk vom Auktionshaus Christie’s für $433.000 versteigert. Das CAN-Netz wurde mit ca. 15,000 gemalten Portraits aus dem 14-18 Jahrhundert trainiert, bevor es „Edmond de Belamy“ kreierte.


